Merging data
Here are some notes on merging data from different data frames. A lot of the functions here come from dplyr, including all the *_join ones.
Types of joins
There are different types of joins that are defined by what data you want to keep and under what circumstances. These are consistent across many different languages (e.g. same terminology in R should apply in most/all SQL variants). The ones you’ll use most often are left joins and inner joins; when in doubt, a left join is safer than an inner join.
There’s an overly complicated chapter in R for Data Science on joins. There are some less complicated examples in the dplyr docs.
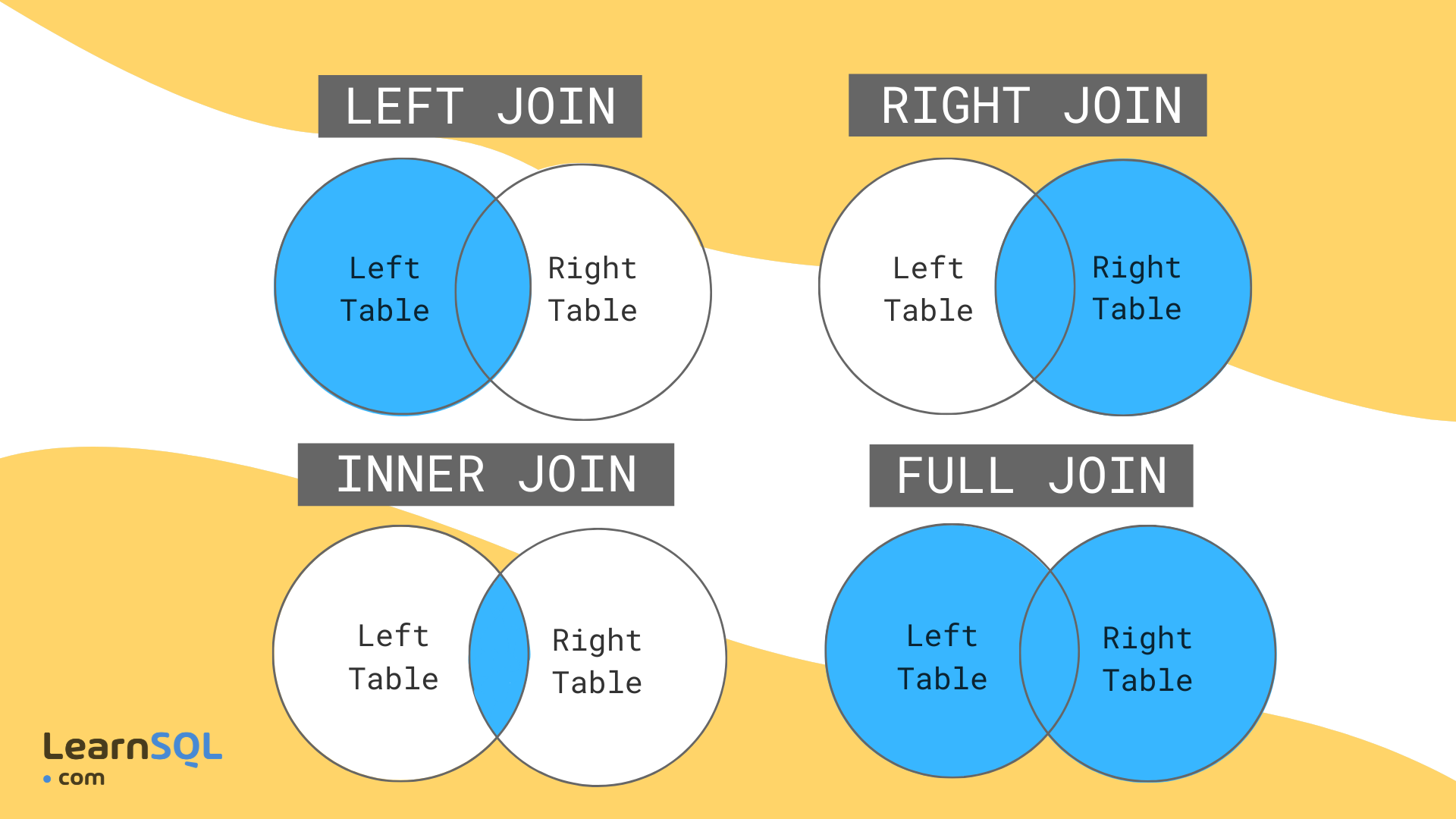
Imagine we’re joining two tables of data for counties A, B, C, D, and E, one row per county. The left table, housing, has housing information for each county but is missing County B. The right table, income, has income information for counties A, B, and E. That means there are a total of 5 counties, but only 2 of them are in both tables.
- Left join will include every county that’s in
housing, regardless of whether it’s also inincome.There will be a row for income variables, but their values will be NA. - Inner join will include every county that’s in both
housingandincome. - Right join is like left join: it will include every county that’s in
income, regardless of whether it’s also inhousing. - Full join will include every county in either table.
set.seed(1)
housing <- data.frame(county = c("A", "C", "D", "E"),
homeownership = runif(4),
vacancy = runif(4, min = 0, max = 0.1))
income <- data.frame(county = c("A", "B", "E"),
poverty = runif(3))
left_join(housing, income, by = "county")| county | homeownership | vacancy | poverty |
|---|---|---|---|
| A | 0.2655087 | 0.0201682 | 0.6291140 |
| C | 0.3721239 | 0.0898390 | NA |
| D | 0.5728534 | 0.0944675 | NA |
| E | 0.9082078 | 0.0660798 | 0.2059746 |
| county | homeownership | vacancy | poverty |
|---|---|---|---|
| A | 0.2655087 | 0.0201682 | 0.6291140 |
| E | 0.9082078 | 0.0660798 | 0.2059746 |
| county | homeownership | vacancy | poverty |
|---|---|---|---|
| A | 0.2655087 | 0.0201682 | 0.6291140 |
| E | 0.9082078 | 0.0660798 | 0.2059746 |
| B | NA | NA | 0.0617863 |
| county | homeownership | vacancy | poverty |
|---|---|---|---|
| A | 0.2655087 | 0.0201682 | 0.6291140 |
| C | 0.3721239 | 0.0898390 | NA |
| D | 0.5728534 | 0.0944675 | NA |
| E | 0.9082078 | 0.0660798 | 0.2059746 |
| B | NA | NA | 0.0617863 |
There are other joins that might be useful for filtering, but that don’t add any new columns. Semi joins return the rows of the left table that have a match in the right table, and anti joins return the rows of the left table that do not have a match in the right table. If you were making separate charts on housing and income, but wanted your housing chart to only include counties that are also in your income data, semi join would help.
Joining justviz datasets
| level | county | name | total_pop | white | black | latino | asian | other_race | diversity_idx | foreign_born | total_hh | homeownership | total_cost_burden | total_severe_cost_burden | owner_cost_burden | owner_severe_cost_burden | renter_cost_burden | renter_severe_cost_burden | no_vehicle_hh | median_hh_income | ages25plus | less_than_high_school | high_school_grad | some_college_or_aa | bachelors | grad_degree | pov_status_determined | poverty | low_income | area_sqmi | pop_density |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| tract | Allegany County | 24001000100 | 3474 | 0.98 | 0.00 | 0.01 | 0.00 | 0.01 | 0.0826466 | 0.01 | 1577 | 0.78 | 0.18 | 0.08 | 0.12 | 0.07 | 0.39 | 0.14 | 0.06 | 56232 | 2671 | 0.09 | 0.47 | 0.28 | 0.07 | 0.08 | 3461 | 0.12 | 0.35 | 187.932766 | 18.48533 |
| tract | Allegany County | 24001000200 | 4052 | 0.75 | 0.19 | 0.02 | 0.00 | 0.03 | 0.4674189 | 0.03 | 1390 | 0.86 | 0.20 | 0.12 | 0.18 | 0.11 | 0.33 | 0.18 | 0.04 | 66596 | 3255 | 0.15 | 0.49 | 0.24 | 0.08 | 0.05 | 2949 | 0.11 | 0.30 | 48.072019 | 84.29020 |
| tract | Allegany County | 24001000500 | 2304 | 0.66 | 0.19 | 0.05 | 0.01 | 0.07 | 0.6236263 | 0.04 | 683 | 0.60 | 0.20 | 0.04 | 0.09 | 0.02 | 0.36 | 0.07 | 0.13 | 47781 | 1283 | 0.09 | 0.37 | 0.38 | 0.11 | 0.06 | 1777 | 0.27 | 0.51 | 4.422954 | 520.91879 |
| tract | Allegany County | 24001000600 | 3005 | 0.91 | 0.02 | 0.01 | 0.00 | 0.07 | 0.2348727 | 0.00 | 1374 | 0.70 | 0.20 | 0.09 | 0.14 | 0.04 | 0.36 | 0.23 | 0.10 | 48607 | 2141 | 0.07 | 0.35 | 0.35 | 0.13 | 0.09 | 2910 | 0.14 | 0.37 | 1.582466 | 1898.93501 |
| tract | Allegany County | 24001000700 | 3233 | 0.93 | 0.02 | 0.01 | 0.00 | 0.04 | 0.1844055 | 0.02 | 1462 | 0.49 | 0.37 | 0.16 | 0.25 | 0.07 | 0.48 | 0.24 | 0.25 | 36090 | 2045 | 0.13 | 0.38 | 0.33 | 0.08 | 0.08 | 3217 | 0.28 | 0.58 | 0.712350 | 4538.49941 |
| tract | Allegany County | 24001000800 | 1932 | 0.89 | 0.01 | 0.06 | 0.01 | 0.03 | 0.2934502 | 0.02 | 786 | 0.48 | 0.52 | 0.25 | 0.35 | 0.19 | 0.68 | 0.30 | 0.17 | 27130 | 1253 | 0.14 | 0.48 | 0.28 | 0.06 | 0.04 | 1926 | 0.35 | 0.61 | 1.263143 | 1529.51773 |
| tract | indicator | value_ptile | d2_ptile | d5_ptile |
|---|---|---|---|---|
| 24001000100 | pm25 | 20 | 18 | 25 |
| 24001000100 | ozone | 7 | 7 | 9 |
| 24001000100 | diesel | 19 | 18 | 24 |
| 24001000100 | air_cancer | 6 | 20 | 31 |
| 24001000100 | air_respiratory | 4 | 14 | 20 |
| 24001000100 | releases_to_air | 44 | 34 | 50 |
ACS data has several geographies, including census tracts (I’ve subset for just tract data). Their ID (GEOID, or FIPS codes) are in the column name. The EPA data is only by tract, and its column of IDs is labeled tract. So we’ll be joining name from acs_tract with tract from ej_natl (this is the nationwide rankings, not the state ones).
There are 15 tracts that are included in the EPA data but not the ACS data. That’s because those are tracts with no population that I dropped from the ACS table when I made it. I can check up on that with an anti-join (not running this here but it confirms that these are all zero-population tracts).
There’s another hiccup for merging data here: the ACS data is in a wide format (each variable has its own column), while the EPA data is in a long format (one column gives the indicator, then different types of values have their own columns). Those formatting differences could be awkward because you’d end up with some values repeated. The easiest thing to do is select just the data you’re interested in, either by selecting certain columns or filtering rows, then reshape, then join.
Let’s say I’m interested in the relationship, if any, between demographics and a few waste-related risk factors (proximity to wastewater, hazardous waste, and superfund sites). I’ll filter ej_natl for just those 2 indicators and reshape it so the columns have the value percentiles for each of those two risk factors (not the adjusted percentiles). Then I’ll select the columns I want from acs, then join them.
The tidyr::pivot_wider and tidyr::pivot_longer functions can be confusing, but there are some good examples in the docs and a lot of Stack Overflow posts on them. Basically here I’m reshaping from a long shape to a wide shape, so I’ll use pivot_wider.
# in practice I would do this all at once, but want to keep the steps separate
# so they're more visible
waste_long <- ej_natl |>
filter(indicator %in% c("haz_waste", "superfund", "wastewater"))
head(waste_long)| tract | indicator | value_ptile | d2_ptile | d5_ptile |
|---|---|---|---|---|
| 24001000100 | superfund | 54 | 43 | 62 |
| 24001000100 | haz_waste | 10 | 10 | 12 |
| 24001000100 | wastewater | 53 | 40 | 58 |
| 24001000200 | superfund | 89 | 73 | 81 |
| 24001000200 | haz_waste | 35 | 43 | 44 |
| 24001000200 | wastewater | 66 | 65 | 69 |
# id_cols are the anchor of the pivoting
# only using value_ptile as a value column, not scaled ones
waste_wide <- waste_long |>
tidyr::pivot_wider(id_cols = tract,
names_from = indicator,
values_from = value_ptile)
head(waste_wide)| tract | superfund | haz_waste | wastewater |
|---|---|---|---|
| 24001000100 | 54 | 10 | 53 |
| 24001000200 | 89 | 35 | 66 |
| 24001000500 | 90 | 42 | 7 |
| 24001000600 | 93 | 50 | 63 |
| 24001000700 | 92 | 60 | 68 |
| 24001000800 | 89 | 78 | 75 |
Then the columns I’m interested in from the ACS data (For good measure, I’ll also add a variable to indicate that a tract is in Baltimore city):
acs_demo <- acs_tract |>
select(name, county, total_pop, white, poverty, foreign_born, homeownership) |>
mutate(is_baltimore = ifelse(county == "Baltimore city", "Baltimore", "Other counties"))
head(acs_demo)| name | county | total_pop | white | poverty | foreign_born | homeownership | is_baltimore |
|---|---|---|---|---|---|---|---|
| 24001000100 | Allegany County | 3474 | 0.98 | 0.12 | 0.01 | 0.78 | Other counties |
| 24001000200 | Allegany County | 4052 | 0.75 | 0.11 | 0.03 | 0.86 | Other counties |
| 24001000500 | Allegany County | 2304 | 0.66 | 0.27 | 0.04 | 0.60 | Other counties |
| 24001000600 | Allegany County | 3005 | 0.91 | 0.14 | 0.00 | 0.70 | Other counties |
| 24001000700 | Allegany County | 3233 | 0.93 | 0.28 | 0.02 | 0.49 | Other counties |
| 24001000800 | Allegany County | 1932 | 0.89 | 0.35 | 0.02 | 0.48 | Other counties |
So each of these two data frames has a column of tract IDs, and several columns of relevant values. I only want tracts that are in both datasets, so I’ll use an inner join.
| name | county | total_pop | white | poverty | foreign_born | homeownership | is_baltimore | superfund | haz_waste | wastewater |
|---|---|---|---|---|---|---|---|---|---|---|
| 24001000100 | Allegany County | 3474 | 0.98 | 0.12 | 0.01 | 0.78 | Other counties | 54 | 10 | 53 |
| 24001000200 | Allegany County | 4052 | 0.75 | 0.11 | 0.03 | 0.86 | Other counties | 89 | 35 | 66 |
| 24001000500 | Allegany County | 2304 | 0.66 | 0.27 | 0.04 | 0.60 | Other counties | 90 | 42 | 7 |
| 24001000600 | Allegany County | 3005 | 0.91 | 0.14 | 0.00 | 0.70 | Other counties | 93 | 50 | 63 |
| 24001000700 | Allegany County | 3233 | 0.93 | 0.28 | 0.02 | 0.49 | Other counties | 92 | 60 | 68 |
| 24001000800 | Allegany County | 1932 | 0.89 | 0.35 | 0.02 | 0.48 | Other counties | 89 | 78 | 75 |
ggplot(waste_x_demo, aes(x = poverty, y = haz_waste)) +
geom_point(aes(color = is_baltimore, shape = is_baltimore), alpha = 0.7) +
scale_color_manual(values = c("purple", "gray60")) +
scale_shape_manual(values = c("circle", "triangle"))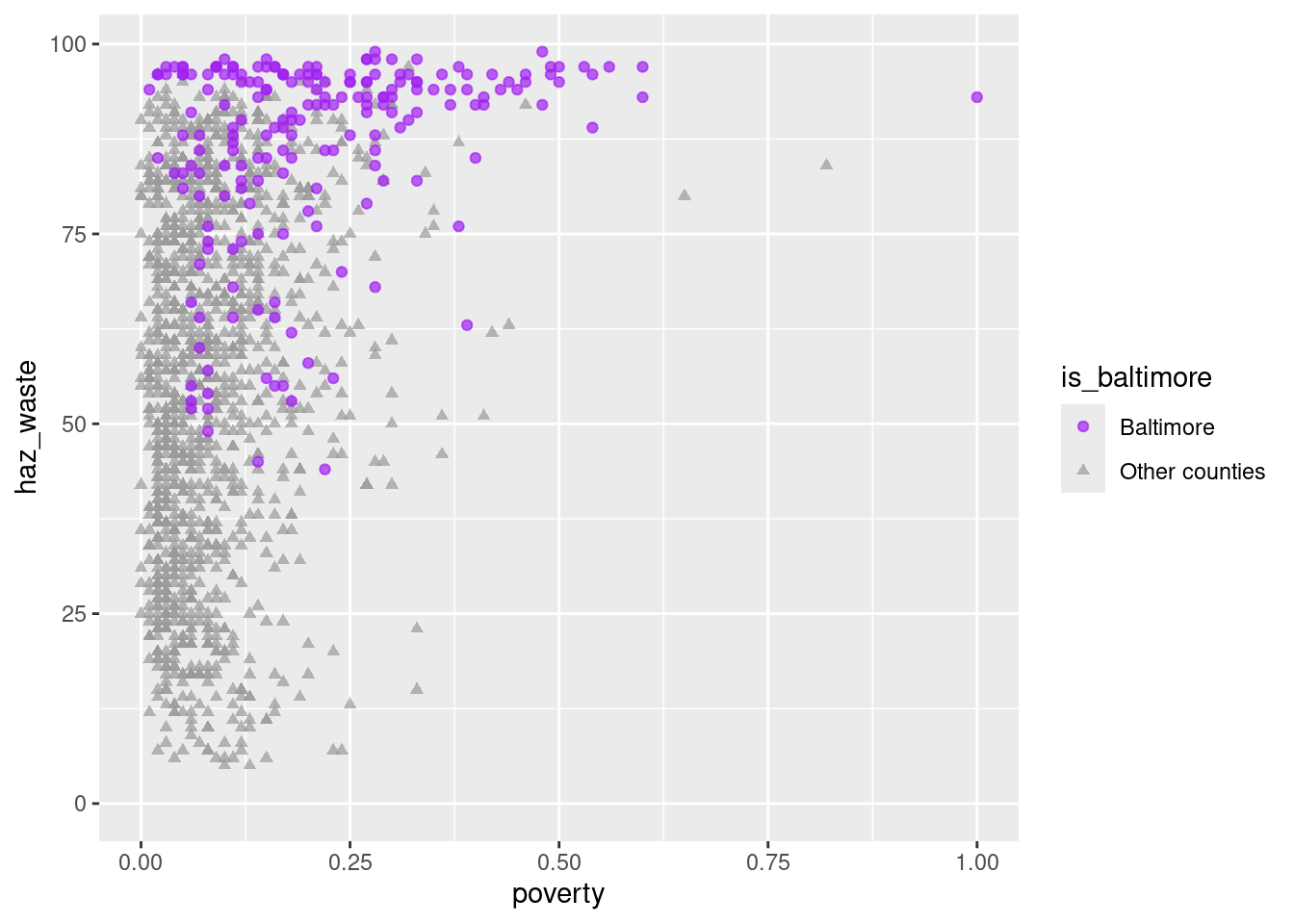
Is there a pattern? Maybe, maybe not, but now we know how to investigate it. There’s definitely something up with Baltimore though.
Joining with a crosswalk
This follows the example in the docs for the justviz::xwalk_tract_10_to_20 dataset. This has columns for 2010 tract GEOIDs, 2020 GEOIDs, and weights to use for converting values based on 2010 geographies to those based on 2020 geographies. This is necessary if you want to join the CDC health data with the ACS or EJSCREEN data, because the CDC data uses 2010 geographies. Let’s expand the example from the docs to merge health indicators with the previous demographic and environmental ones—say we want to know if there’s a relationship between adult asthma rates and waste-related risks.
# these are based on 2010 geographies
asthma10 <- cdc |>
filter(level == "tract",
indicator == "Current asthma")
head(asthma10)| level | year | location | indicator | value | pop |
|---|---|---|---|---|---|
| tract | 2021 | 24005408200 | Current asthma | 8.6 | 1853 |
| tract | 2021 | 24003706700 | Current asthma | 8.8 | 4890 |
| tract | 2021 | 24015030506 | Current asthma | 11.1 | 8223 |
| tract | 2021 | 24005401301 | Current asthma | 11.3 | 3891 |
| tract | 2021 | 24005411302 | Current asthma | 9.3 | 3310 |
| tract | 2021 | 24005402403 | Current asthma | 11.3 | 2283 |
# calculate a weighted mean of 2010 tract rates, weighted sum of 2010 counts (pop)
# both grouped by 2020 tract
asthma20 <- asthma10 |>
inner_join(xwalk_tract_10_to_20, by = c("location" = "tract10")) |>
group_by(tract20) |>
# don't know why cdc rates aren't divided by 100 so do it now
summarise(asthma = weighted.mean(value, weight) / 100,
adult_pop = sum(pop * weight)) |>
ungroup()
waste_x_demo_x_cdc <- waste_x_demo |>
left_join(asthma20, by = c("name" = "tract20"))
head(waste_x_demo_x_cdc)| name | county | total_pop | white | poverty | foreign_born | homeownership | is_baltimore | superfund | haz_waste | wastewater | asthma | adult_pop |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 24001000100 | Allegany County | 3474 | 0.98 | 0.12 | 0.01 | 0.78 | Other counties | 54 | 10 | 53 | 0.1040000 | 3718.000 |
| 24001000200 | Allegany County | 4052 | 0.75 | 0.11 | 0.03 | 0.86 | Other counties | 89 | 35 | 66 | 0.0920000 | 4564.000 |
| 24001000500 | Allegany County | 2304 | 0.66 | 0.27 | 0.04 | 0.60 | Other counties | 90 | 42 | 7 | 0.1149507 | 2735.419 |
| 24001000600 | Allegany County | 3005 | 0.91 | 0.14 | 0.00 | 0.70 | Other counties | 93 | 50 | 63 | 0.1038916 | 2979.443 |
| 24001000700 | Allegany County | 3233 | 0.93 | 0.28 | 0.02 | 0.49 | Other counties | 92 | 60 | 68 | 0.1160000 | 3387.000 |
| 24001000800 | Allegany County | 1932 | 0.89 | 0.35 | 0.02 | 0.48 | Other counties | 89 | 78 | 75 | 0.1190000 | 2213.000 |
So now we’ve got a data frame with some demographic indicators, some environmental risks, and rates of a major health outcome. Expanding the previous question to include asthma rates:
ggplot(waste_x_demo_x_cdc, aes(x = haz_waste, y = asthma)) +
geom_point(aes(color = is_baltimore, shape = is_baltimore), alpha = 0.7) +
scale_color_manual(values = c("purple", "gray60")) +
scale_shape_manual(values = c("circle", "triangle"))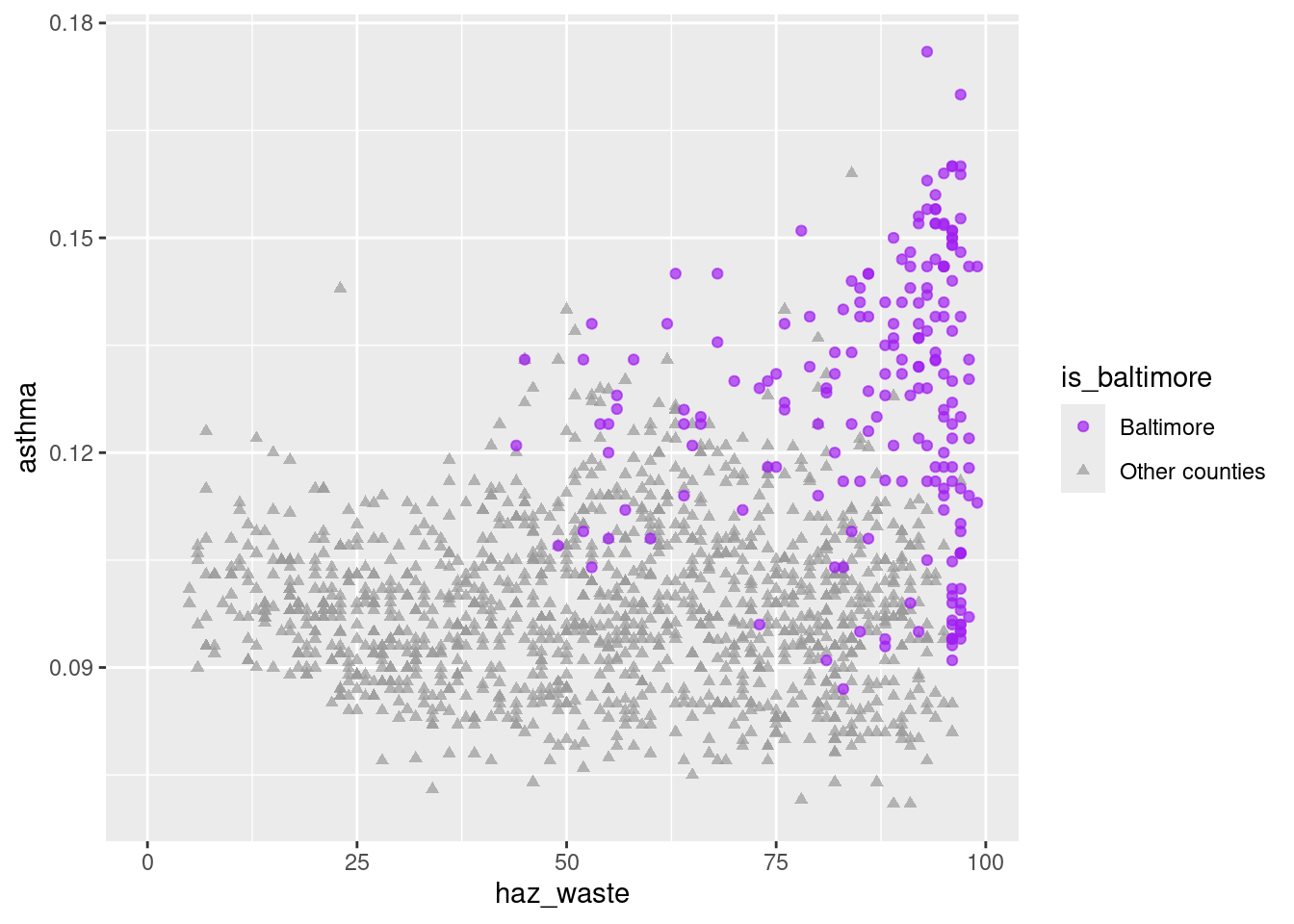
So there does seem to be a correlation between the two variables, with Baltimore city tracts standing out on both. 1
1 It’s worth noting that the CDC data uses crude rates, not age-adjusted ones, which we don’t have to get into but it becomes important with age-related health conditions like cancer. That’s why I chose asthma instead.
Joining data with different shapes
Last, an example of a situation where you might want to join one long data frame with one wide one. If I want to compare poverty rate to each of the waste risk factors, and create small multiple charts, I’ll need a variable to facet on. So I’ll go back to waste_long and join that to the ACS data. Because of those differing shapes, the ACS data will be repeated, once for each waste indicator.
waste_long_x_demo <- waste_long |>
inner_join(acs_demo, by = c("tract" = "name")) |>
select(tract, is_baltimore, indicator, value_ptile, poverty)
head(waste_long_x_demo)| tract | is_baltimore | indicator | value_ptile | poverty |
|---|---|---|---|---|
| 24001000100 | Other counties | superfund | 54 | 0.12 |
| 24001000100 | Other counties | haz_waste | 10 | 0.12 |
| 24001000100 | Other counties | wastewater | 53 | 0.12 |
| 24001000200 | Other counties | superfund | 89 | 0.11 |
| 24001000200 | Other counties | haz_waste | 35 | 0.11 |
| 24001000200 | Other counties | wastewater | 66 | 0.11 |
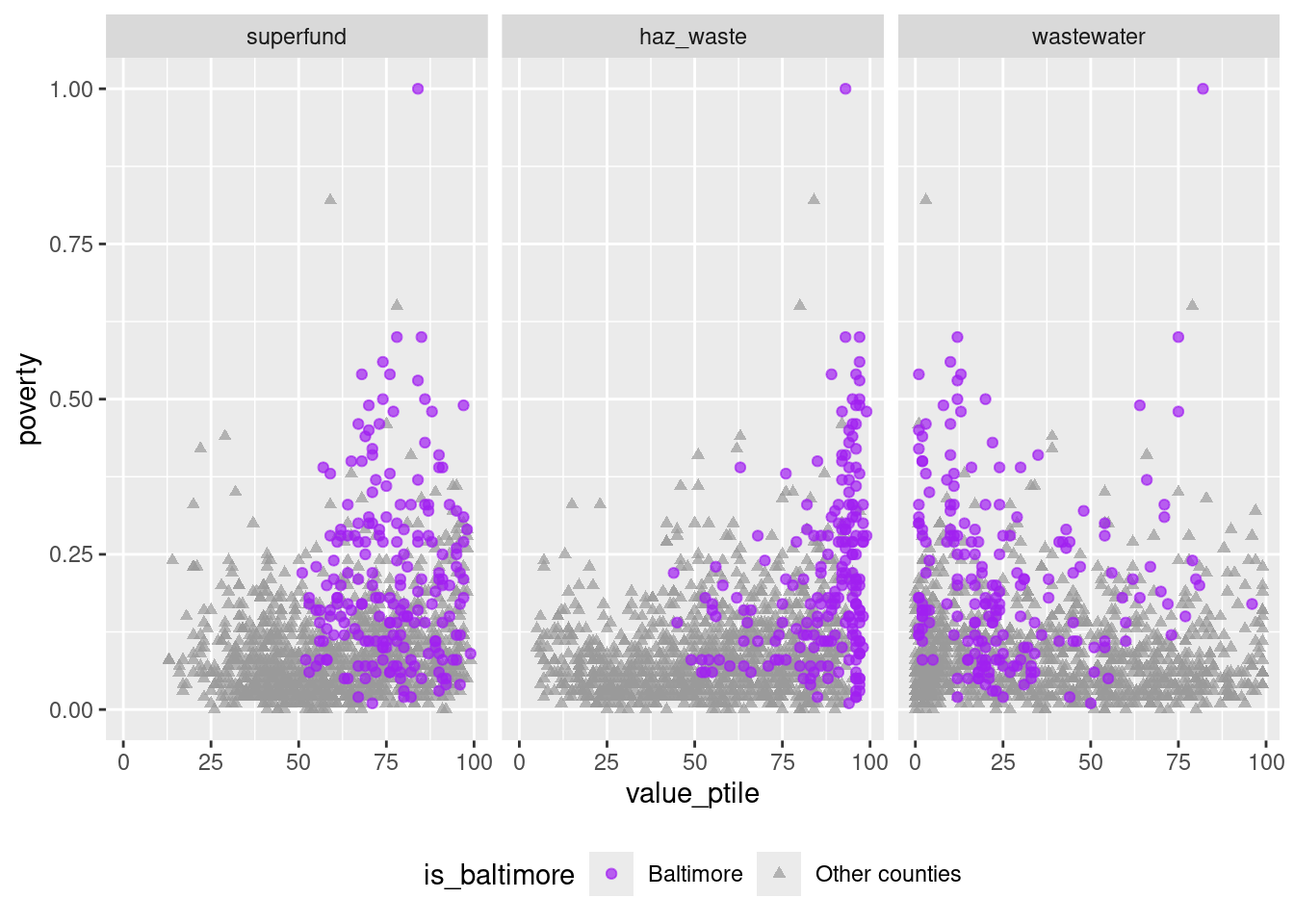
As you can see, the first of these tracts (24001000100) takes up 3 rows, one for each of the 3 waste indicators. To match it, that tract’s poverty rate (0.12) is repeated 3 times.
ggplot(waste_long_x_demo, aes(x = value_ptile, y = poverty)) +
geom_point(aes(color = is_baltimore, shape = is_baltimore), alpha = 0.7) +
scale_color_manual(values = c("purple", "gray60")) +
scale_shape_manual(values = c("circle", "triangle")) +
facet_wrap(vars(indicator), nrow = 1) +
theme(legend.position = "bottom")